Drink.csv 데이터에 대한 변수 간 상관관계 분석 후 분포 시각화
1. Python에서 pandas, numpy 및 matplotlib 모듈 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ddf = pd.read_csv('./data/drinks.csv')
print(ddf)
2. 상관 계수 “맥주 부분” 및 “주류 부분”(Pearson 상관 계수)

맥주와 함께 spirit_servings의 Pearson 상관계수는 0.458819로 0.5보다 작으므로 두 변수 사이에 약한 상관관계가 있음을 알 수 있다.
corr_beer_spirit = ddf(('beer_servings','spirit_servings'))
corr_beer_spirit.corr(method='pearson')
3. 상관 계수 “beer_servings”, “spirit_servings”, “total_litres_of_pure_alcohol”을 히트맵으로 표시

colum = ('beer_servings','spirit_servings','total_litres_of_pure_alcohol')
print(colum)
corr_b_s_t = ddf(colum).corr(method='pearson')
print(corr_b_s_t)
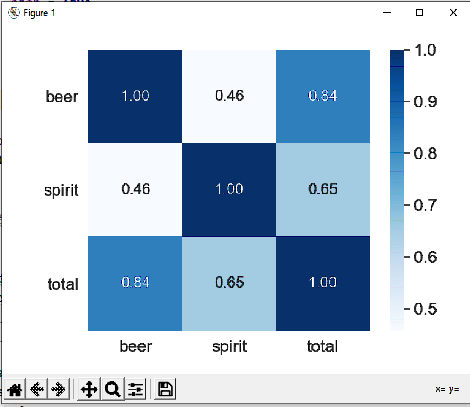
상관관계가 가장 강한 특성은 상관계수가 0.84인 beer_servings와 total_liters_of_pure_alcohol입니다.
또한 정신_portions와 함께 total_liter_of_pure_alcohol의 상관계수는 0.65로 0.5보다 크므로 강한 상관관계가 있다고 볼 수 있다.
import seaborn as sns
view = ('beer','spirit','total')
sns.set(font_scale=1.5)
hmap = sns.heatmap(corr_b_s_t.values,
cmap = 'Blues',
cbar = True,
annot = True,
square = True,
fmt=".2f",
annot_kws = {'size':15},
xticklabels = view,
yticklabels = view,)
plt.yticks(rotation=0)
plt.tight_layout()
plt.show()
4. 위의 상관계수를 그래프(페어 플롯)로 표시합니다.
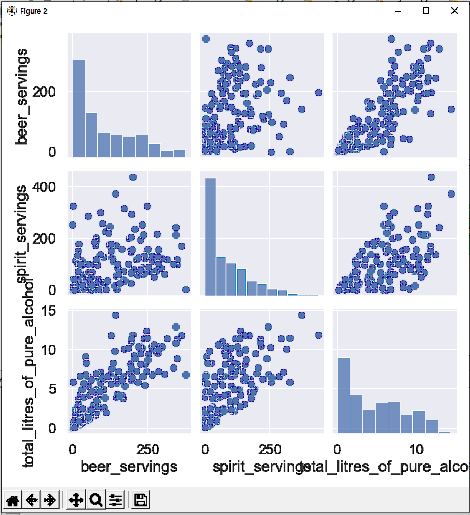
각 변수의 상관계수는 pair plot으로 나타내었다. 차트를 보면 각 변수가 양의 상관관계를 갖고 있음을 알 수 있습니다.
sns.set(style="darkgrid",context="talk") #사이즈 선택 : context =paper,notebook,talk,poster
sns.pairplot(ddf(colum),height=2.5) #style 테마 지정 : darkgrid, whitegrid,dark,white,ticks
plt.show()